SiLVi: Simple Interface for Labeling Video Interactions
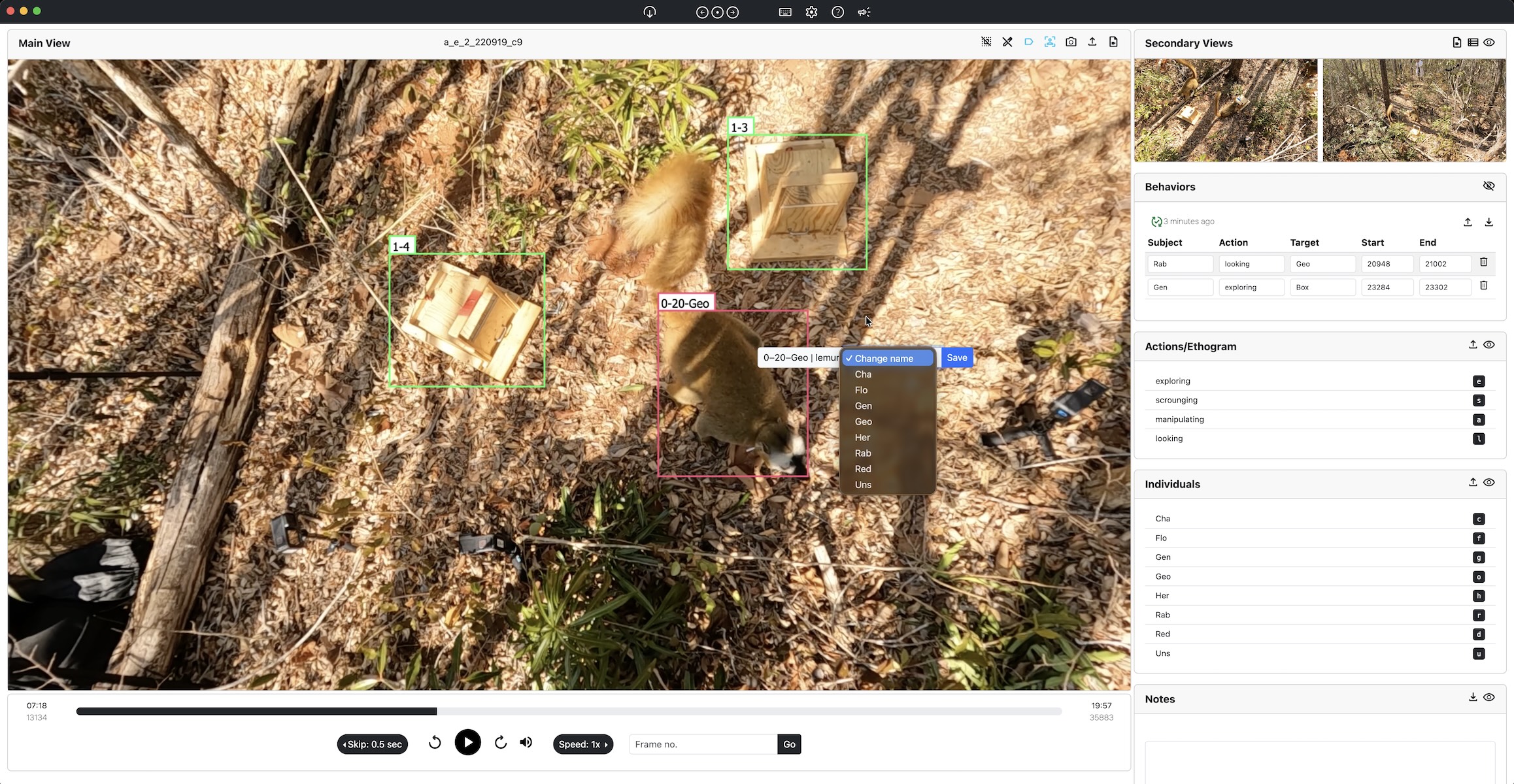
SiLVi is a lightweight, open-source tool designed specifically to facilitate the annotation of video interactions in a way that is both spatially and temporally localized, enabling the generation of training data for computer vision models.
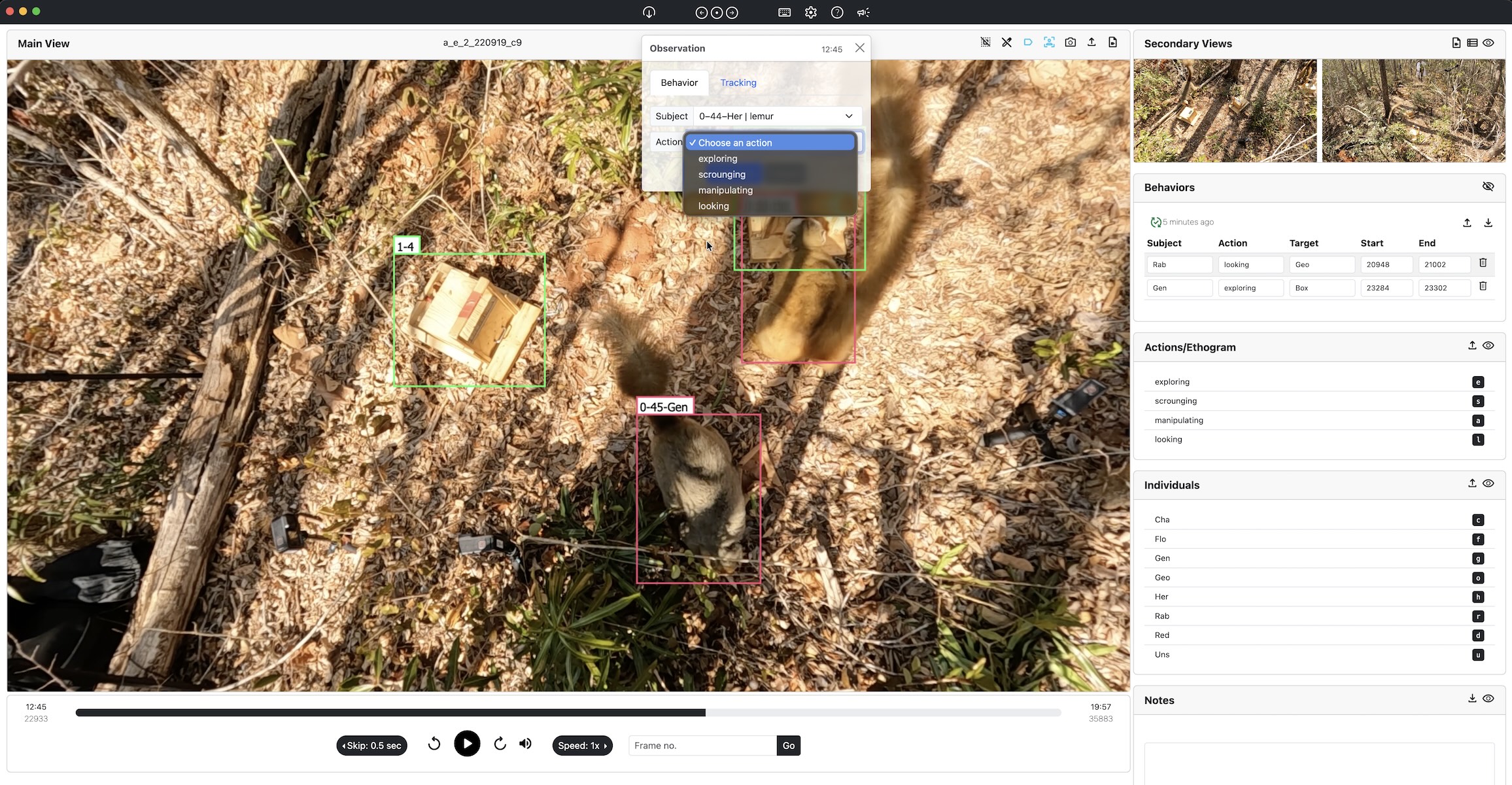
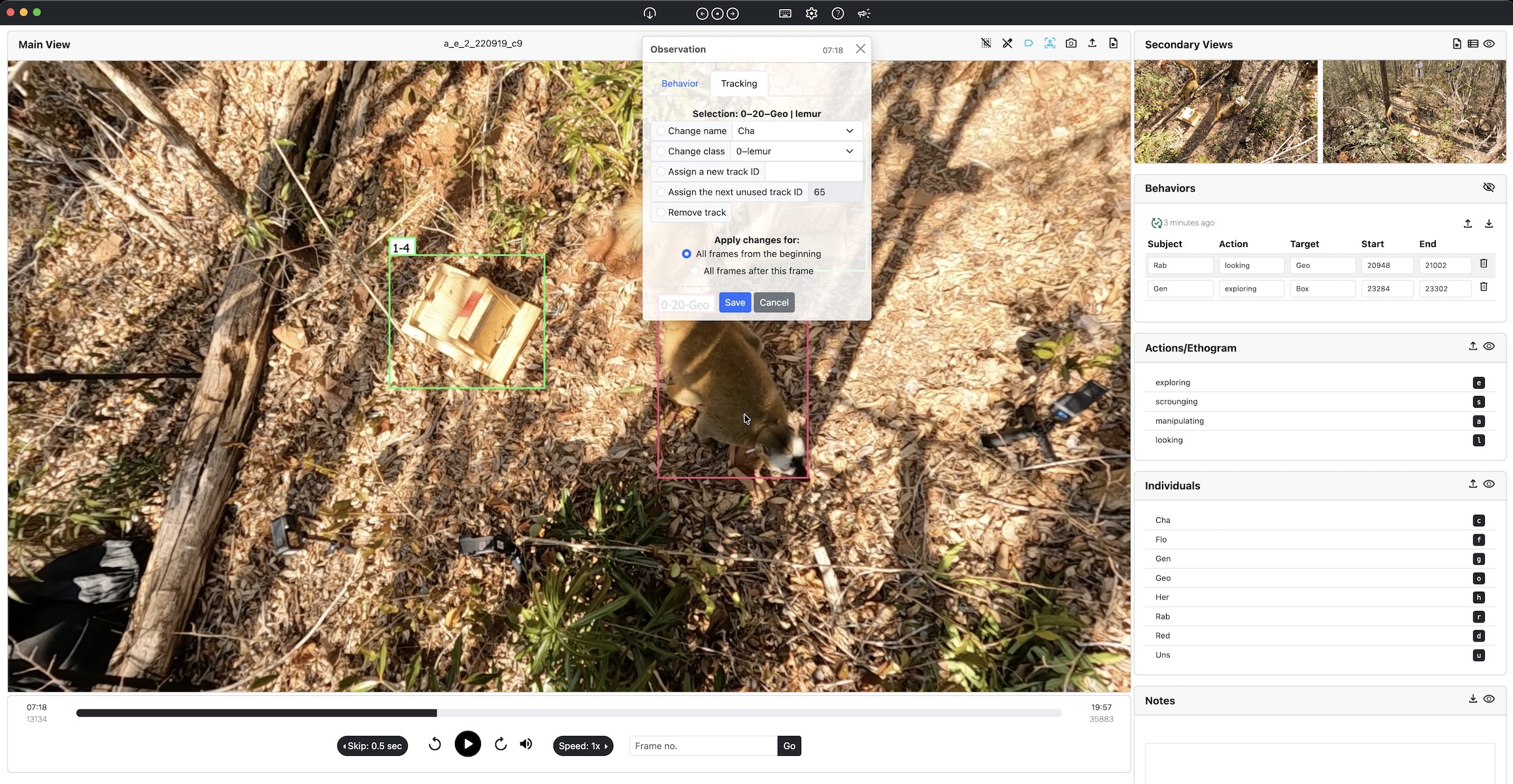
By supporting precise annotations of both actions and interactions across individuals, SiLVi empowers researchers to move beyond individual-centric behavioral models toward richer representations of social behavior. Apart from this main contribution, SiLVi also allows for labeling individual IDs and annotating or correcting tracks.
You can read our preprint here. If you use SiLVi in your research, please cite it.